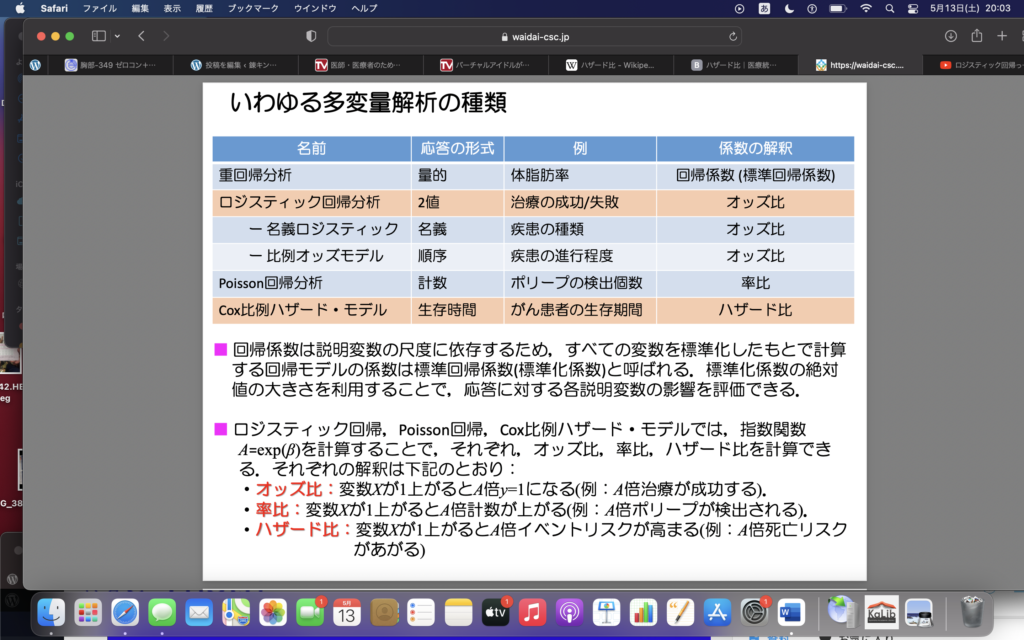
数学では多変数といったのに、統計学では多変量という。変なの。
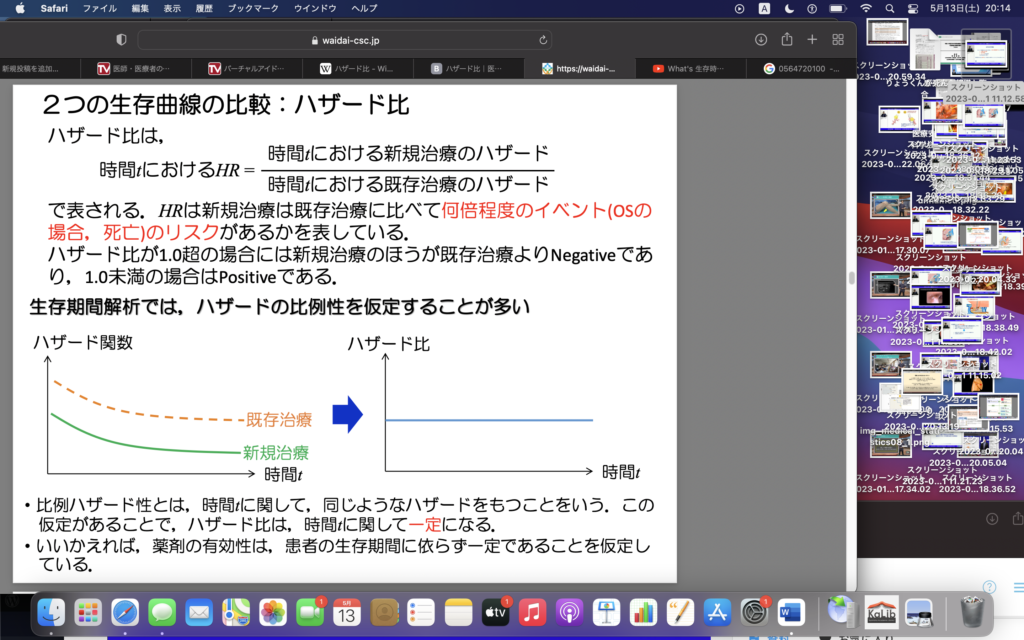
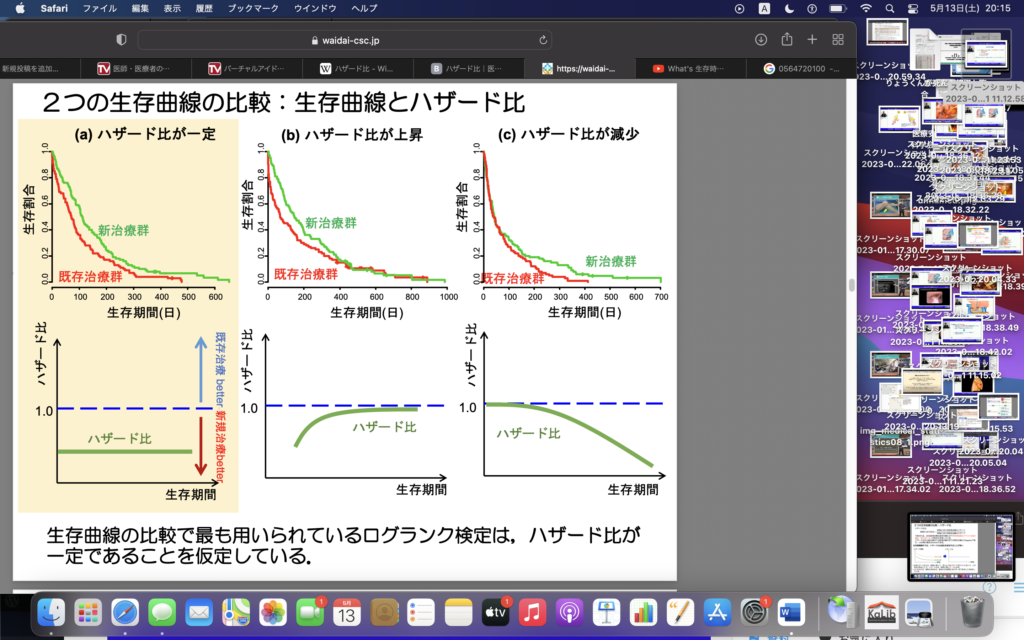
Cox比例ハザードモデルはproportional hazard(比例ハザード性)を仮定している。
「多変量Cox比例ハザード解析がわからない」という人は
・多変量解析がわからないのか?→多変量解析は、交絡因子を取り除くために行う。多変数でも、単変量解析を何度も行う方法もある。多変量解析やった場合は、普通単変量解析の結果とならべて表示するのが一般的。傾向スコアマッチングとかで補正した場合は、そもそも多変量解析をやる必要がない(←2024/2/9追記)
・比例ハザードモデルがわからないのか?→比例ハザードというすんごい特殊な世界(状況?)をベースにしてる ハザード比を、時間によらず一定と仮定してモデルの式をつくっている。モデルの式において、独立変数は予後因子になることが多く、ダミー変数を使っている。
・結果の解釈がわからないのか?→モデル式で、変数ごとのHRの信頼区間を出して(その変数がハザード比を何倍にするか)その信頼区間が1より小さければ、とりあえずいいと言える。変数の選択がちゃんとできているかは、検定をして確かめる。どれくらいの精度で予測してますか?てことよね。
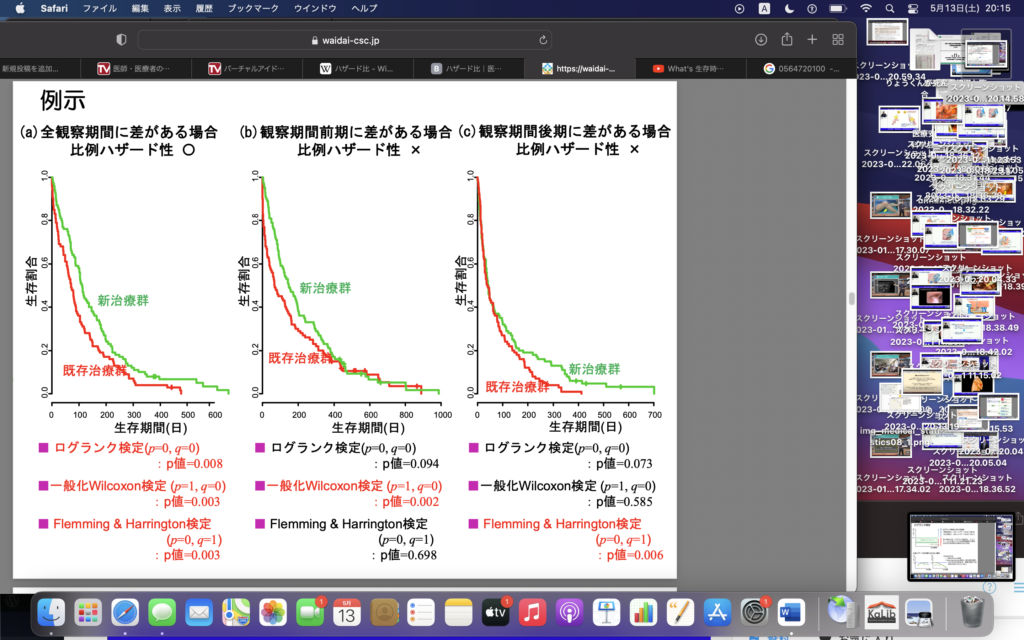
(https://www.youtube.com/watch?v=oQQUSsWS4lE)単変量の場合は、ログランク検定をやってもいいし、Cox単変量解析をやってもよいです。p値もほぼ同じ。
ハザード比 偏回帰係数のexpがハザード比になるの。なぜ?モデル式をみればわかるね。
そして95%信頼区間の95%とは、確率ではなく割合である。この区間推定を100回やったら、100個の95%信頼区間がでてくるけど、そのうち95個は区間の中に真の値を含む、という考え方。(95%の確率で、信頼区間の中に真の値を含む、と勘違いしやすい)
どれがわからないのか?をよく考えたほうがいい。
Toshiは全部わからなかった。笑
p値は、特に意味もなく「たまたまその結果になる」確率。

比例ハザード性を仮定するって、なんというか、すごく傲慢だよね(笑)

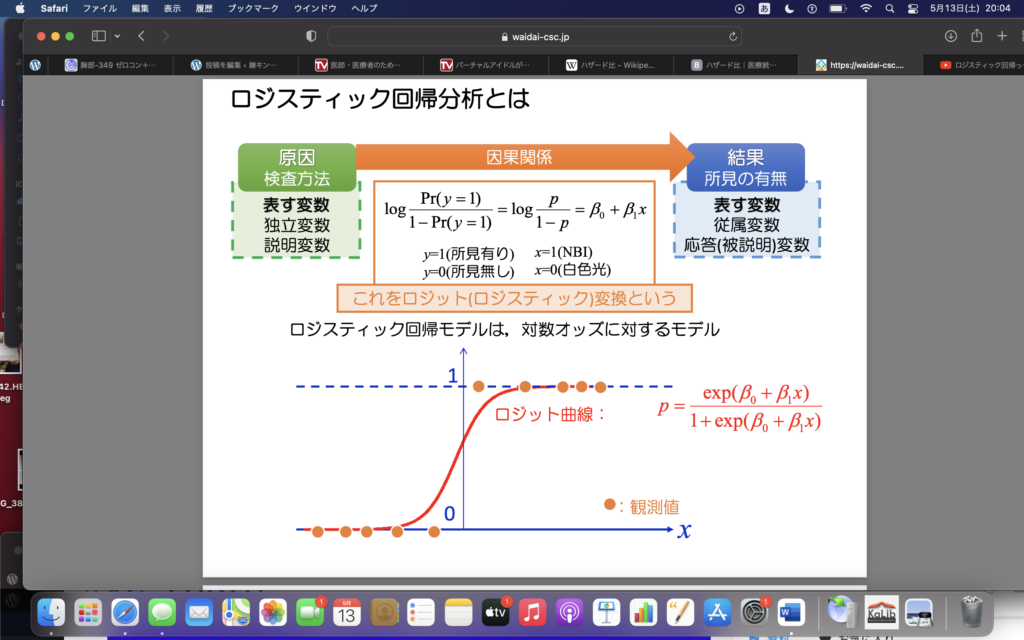
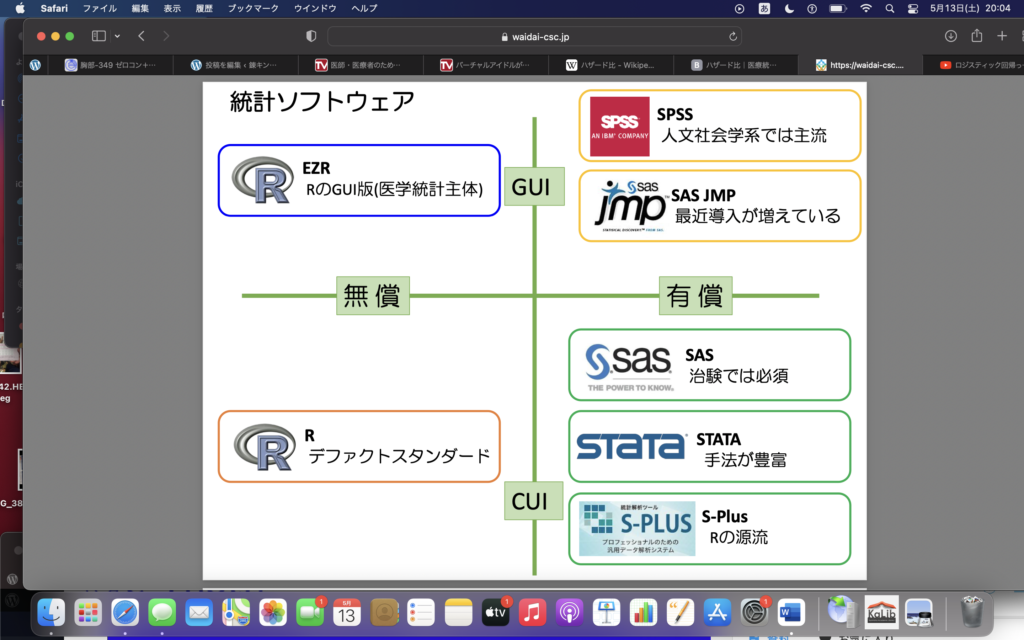
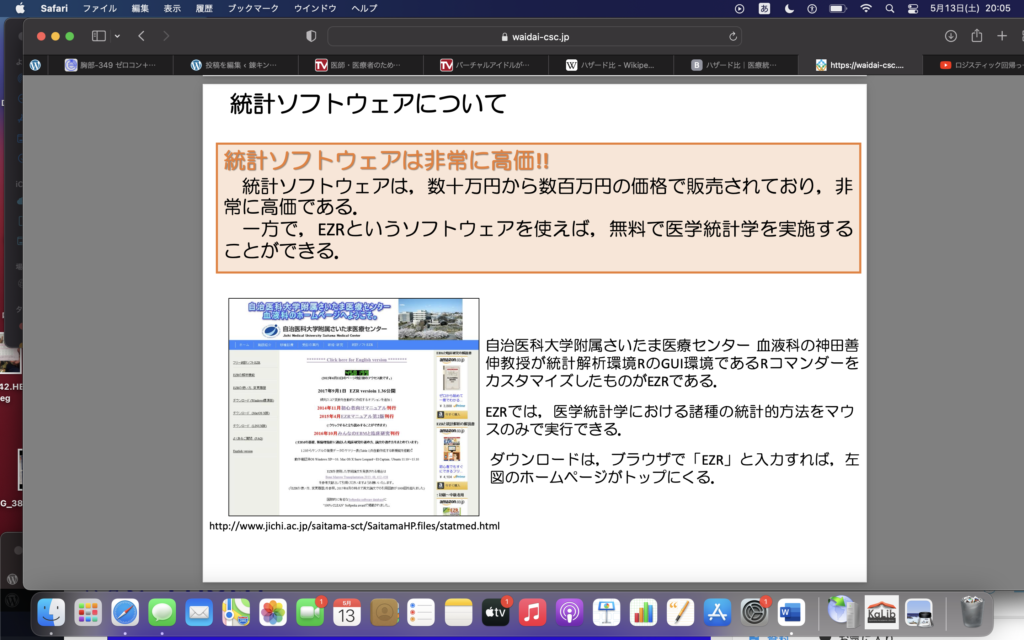
(2023/5/31追記)
打ち切りの縦線で、曲線が下がるというわけではない。
じゃあ抄読会でYN先生が言ってたこととは?「打ち切り多くね?笑」って話か


